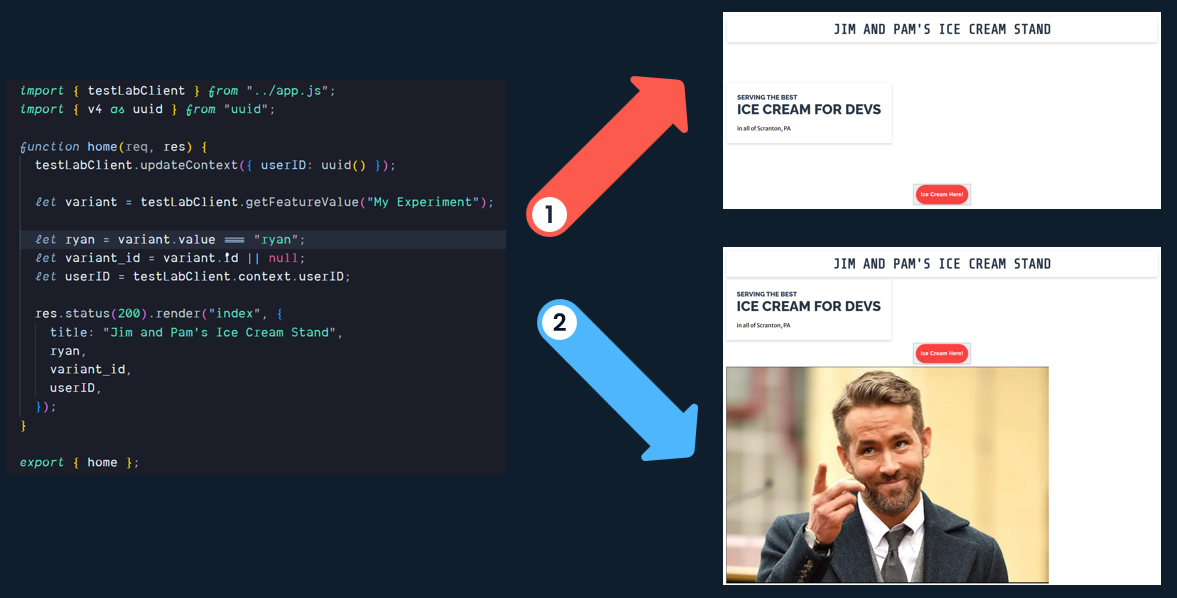
Test Lab Architecture
SDK
Test Lab provides native SDKs for Node, React, Ruby, and Python. Instructions for using the SDKs can be found in the SDK documentation.
What does the SDK do?
The SDK stores an in-memory representation of the current configuration of features that could be available for a particular user. Because the SDK client caches all features and their current configuration in memory, it is very efficient to determine the value of a feature (i.e., determine whether the feature is active or inactive for a user and, if appropriate, which variant the user should experience), as it is a function operating on a local state without the need to retrieve data from a database.
When provided with a unique string to identify a user (stored as a user_id), the SDK client can determine the value of each feature for that user deterministically without making any additional API calls to the Test Lab backend server.
How SDKs receive updated feature data
Test Lab relies on SDKs fetching features in the background using polling at regular intervals. In a thread-based environment, this needs to be done in a separate thread. The poll interval is configurable in the SDK and will depend on how often feature updates are made.
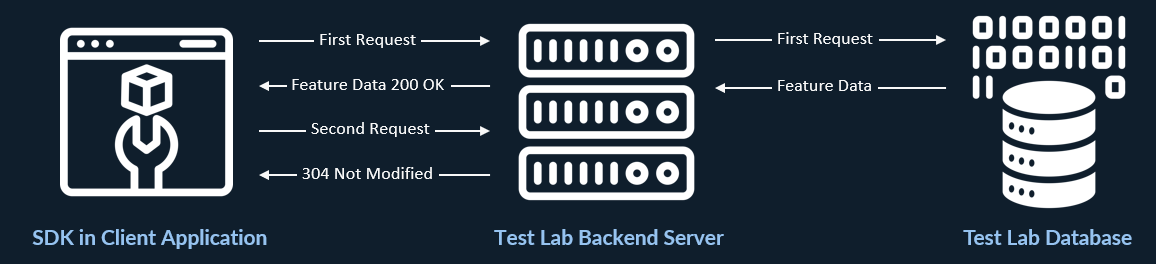
The first time that the SDK client fetches feature configurations, it makes a request to the Test Lab backend server, the server reaches out to the database to retrieve the current feature and user-block configuration, and the current configurations are returned to the SDK client with a 200 OK status.
Once the initial fetch is complete, the SDK client sends subsequent requests at the specified intervals with a If-Modified-Since header. The Test Lab backend server keeps track of the last time feature data was modified, and it simply returns a 304 Not Modified status if no changes have been made since the last request. This is critical because it prevents the backend server from making an unnecessary call to the database to retrieve data that has not been modified. On the other hand, if changes have been made, then the updated feature configuration data is returned, and the in-memory representation of the feature configuration is updated by the SDK.
How feature evaluation works
To determine the value of (i.e., evaluate) a feature, the SDK considers several attributes of a feature, all of which are stored in or can be calculated from the in-memory representation of the feature configuration:
- Is the feature active or paused?
- Is the current date within the start and end date of the scheduled feature
- If the feature is a rollout or an experiment, what percentage of users should be exposed to the feature?
- If the feature is an experiment, is the experiment active for this particular user?
- If the experiment is active for this user, to which variant should the user be exposed?
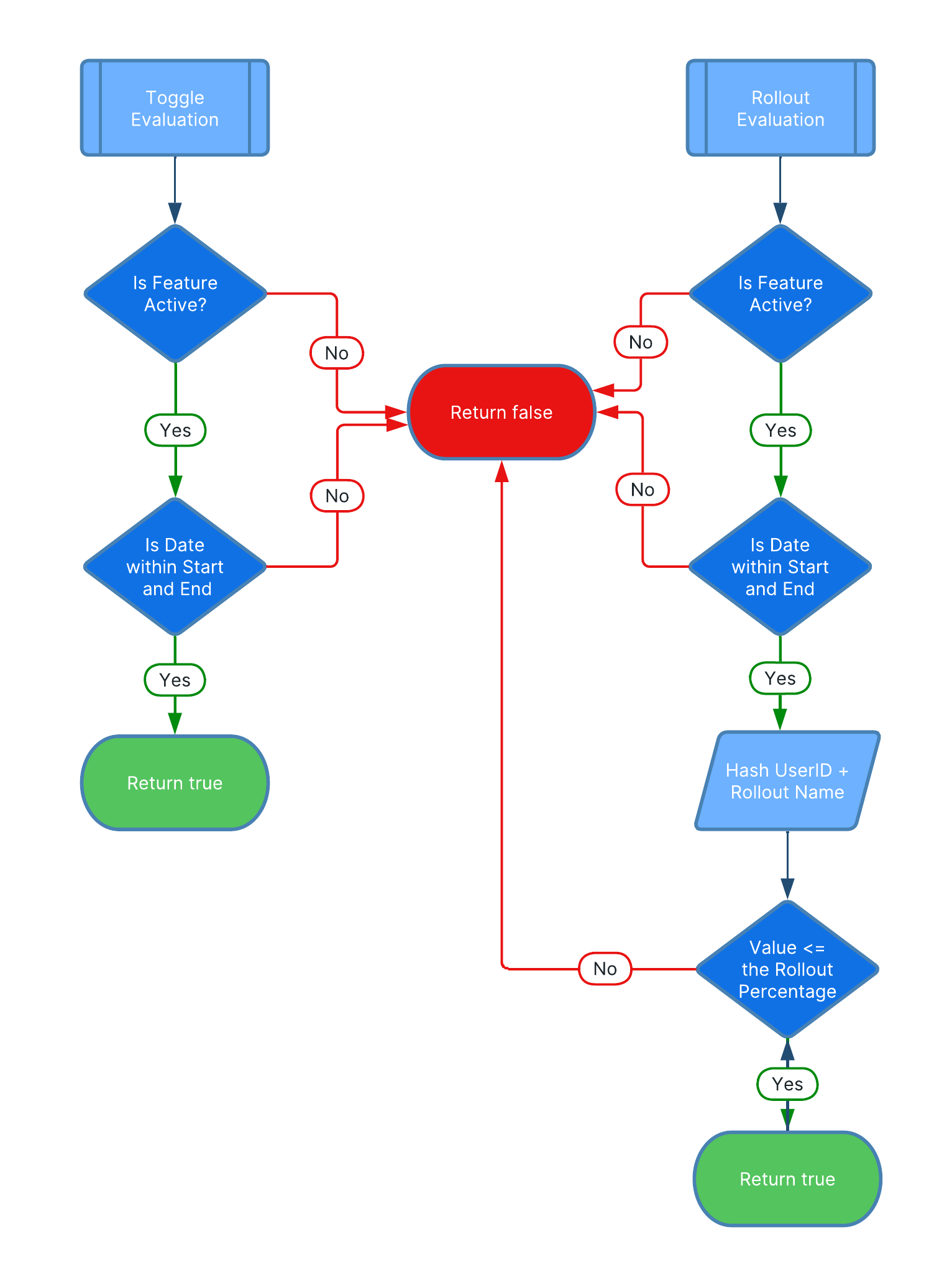
Toggle and rollout evaluation
When evaluating whether a feature toggle is active for a particular user, the SDK checks whether the current date is within the start and end date for a particular toggle and whether the toggle is currently active (i.e., not paused). If both of these are true, then the SDK returns true for this feature.
For a rollout, the same initial checks on the date range and the active status of the rollout are performed. If either is false, then the SDK returns false for the feature. If both are true, then the SDK uses a hashing function to hash the concatenated string of the user_id and the rollout name into a value between 0 and 1. If this value is less than or equal to the rollout percentage expressed as a decimal value, then the SDK returns true for this feature.
In other words, for a rollout percentage of 10%, the rollout would return true for a user if the hashed value of the user_id concatenated to the rollout name is less than or equal to 0.10.
Why hash the concatenated string?
It would be valid to question why we chose to hash the concatenated string of the user_id and the rollout name instead of just hashing the user_id.
We made the choice to hash the concatenated string because, in contrast to the experiment feature type described below, there is no constraint on the number of rollouts that a user can be exposed to. However, we do want to make sure that users are uniformly distributed amongst active rollouts.
Let’s suppose that we have three active rollouts:
- Rollout 1 is active for 10% of users
- Rollout 2 is active for 20% of users
- Rollout 3 is active for 30% of users
Let’s also suppose that we have a user_id that hashes to a value of 0.06. If we just used this value to determine rollout activity, all three rollouts would be active for this user, as 0.06 is less than 0.10, 0.20, and 0.30! In contrast, a user with a user_id that hashes to a value of 0.35 would have no active rollouts.
By hashing the user_id concatenated to the rollout name we ensure that the hashed value for an individual user is different for each rollout, resulting in a more uniform distribution of rollouts across the user base.
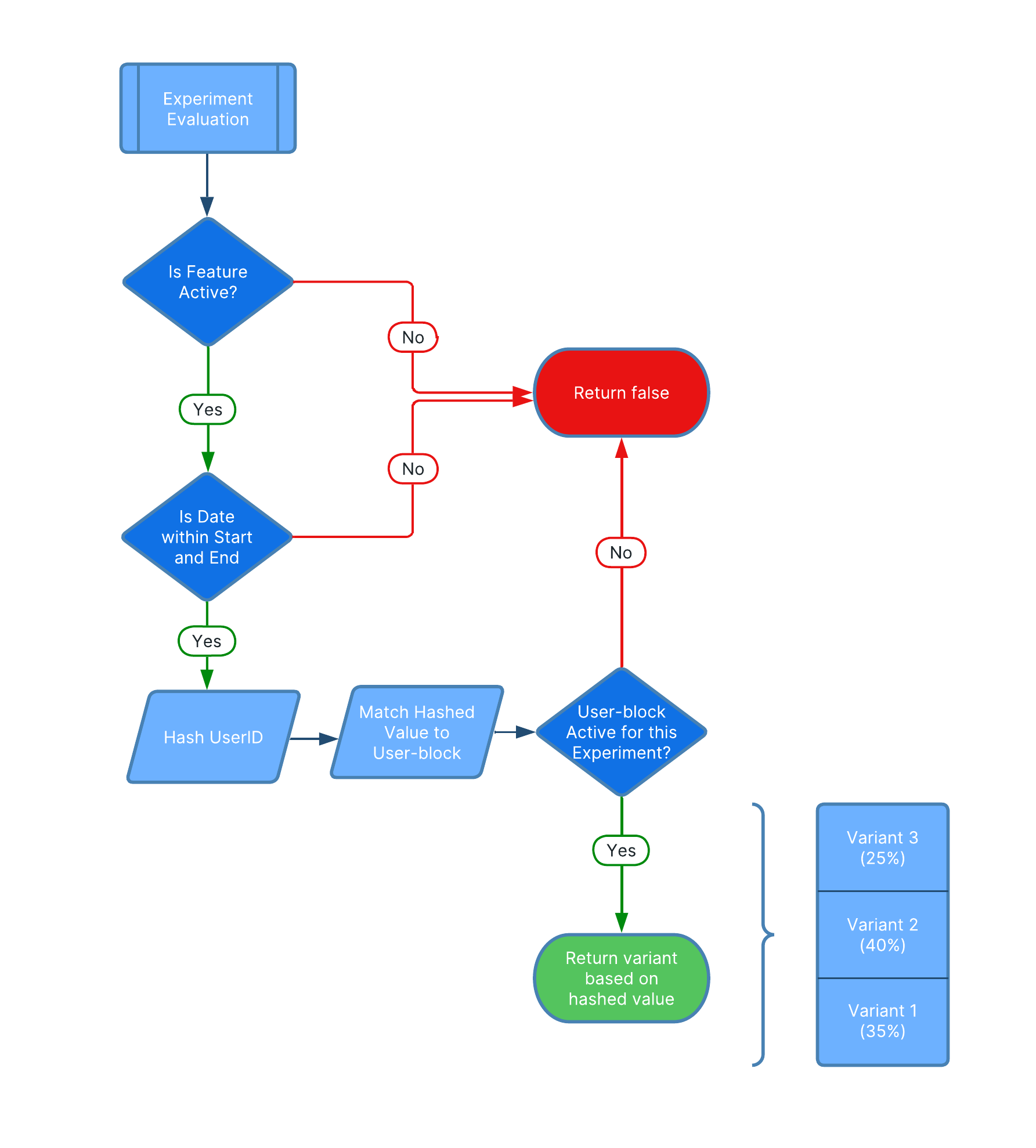
Experiment evaluation
When evaluating the value of an experiment feature, Test Lab starts with the standard checks of whether or not the feature is active and whether we are within the prescribed start and end dates of the experiment. If both are true, then the SDK uses the hashing function to hash the user_id to a value between 0 and 1. A user can be assigned to only one experiment at a time, so we do not need to worry about the overlapping issue addressed in the feature toggle discussion above.
User-blocks
Our solution for ensuring that users are assigned to no more than one experiment relies on user-blocks. When a new experiment is created, the Test Lab backend server works with the Admin UI to ensure that no more than 100% of users are assigned to be in a concurrent experiment. Test Lab allocates “blocks” of users in 5% increments. Once a user-block is assigned to a particular experiment, it remains assigned to that experiment through its conclusion. After the experiment completes, that user-block segment is available for another experiment. The key is that once a user-block is assigned to a particular experiment, it is occupied for the duration of that experiment.
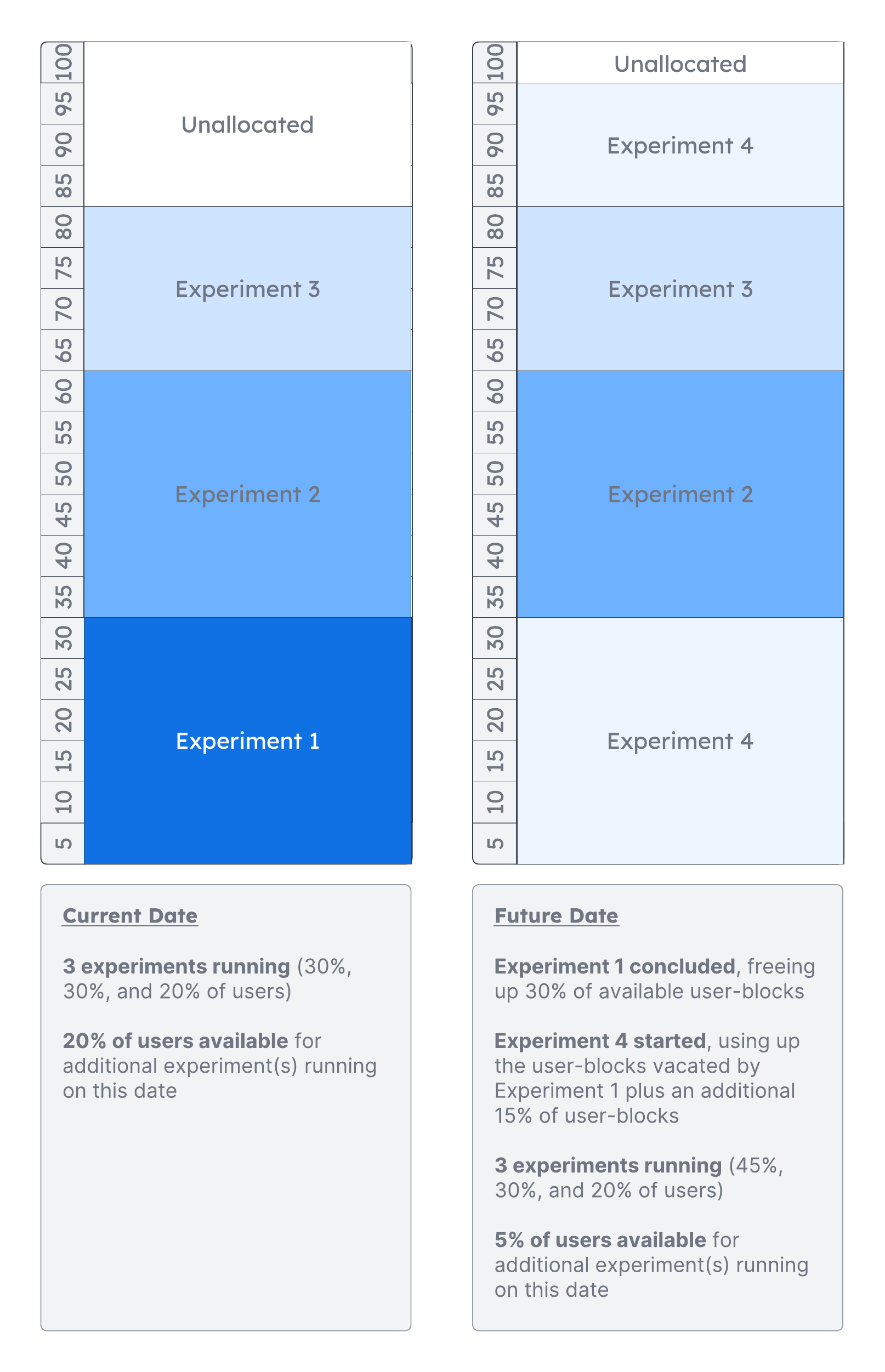
The concept of user-blocks is critical for understanding the evaluation of experiment features by the SDK, as the Test Lab assignment logic hashes the user_id to a value between 0 and 1, then matches that hashed value to a particular user-block. If the hashed value is 0.54, it would be matched to the user-block that represents the 50% - 55% range of users.
Once a user-block has been identified, the SDK checks whether or not that user-block is active for this particular experiment. If it is, then it returns a variant based on the hashed value and the weight of the variants for this particular experiment. For example, in our example where the user_id has a hashed value of 0.54, and the 50% - 55% user-block is active for our experiment, then we would look to the distribution of variants to determine which variant to serve the user.

Overall, the process that a Test Lab SDK uses to determine the value of an experiment feature is outlined by the flowchart below.
Variants that are returned by the Test Lab SDK include both a value and an id property. The value property is used by the developer to render the correct version of the feature for a user, and the id property is used (in conjunction with the user_id) to send event data to the Test Lab backend server for collection, analysis, and visualization in the Admin UI.